Python 코드 짜깁기: Google News 검색 결과 스크랩해서 저장하기
파이썬으로 구글 뉴스 스크랩하기
요즘 개인적으로 공부하고있는 것들이 많은데, 그 분야의 자료들 또는 뉴스 헤드라인을 모아서 한 번에 볼 수 있으면 좋겠단 생각이 들었다. 그동안 공부하면서 연습해본 BeautifulSoup나 Selenium을 이용해서 Google News의 검색 결과를 csv, xlsx 파일로 저장할 수 있는 코드를 짜보았다.
ToC는 다음과 같다.
1. 어떤 코드를 참고해서 만들까?
일단 맨땅에 헤딩하기엔 내 실력이 부족하기도 하고, 다른 사람들이 예제로 많이 만들어둔 코드들이 있을거라 생각해서 몇몇 블로그와 강의를 찾아봤다. 여기1와 여기2에 올라와있는 코드를 주로 참고했고, 약간의 변형을 했다. input() 함수를 사용해서 검색어를 입력받아서 결과를 출력할 수 있는 내용으로 만들었다.
일단 가장 먼저 복습할 겸 찾아본건 wikidocs의 파이썬 레시피 - 웹 활용 입문편3이다. 이전에 예제 따라해보면서 bs4랑 selenium, requests은 pip로 다 설치했었고, chromedriver도 다운받았다.
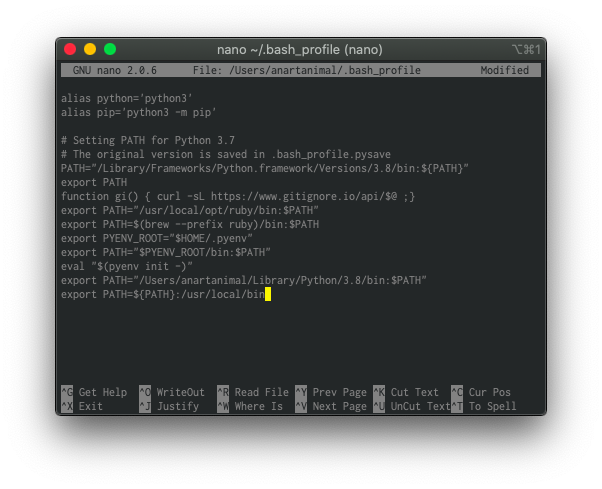
지금 MacOS를 쓰고있는데, 여기4내용 참고해서 검색하다보니 chromedriver를 /usr/local/bin에 저장하고 export PATH=${PATH}:/usr/local/bin 등록하면 일일히 경로 지정을 안해도 된다길래 그대로 따라했다.
$ nano ~/.bash_profile
$ nano ~/.zshrc
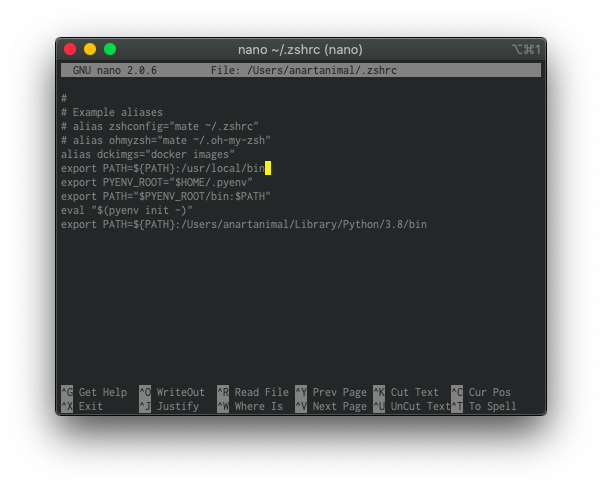
나는 지금 iTemr을 깔아서 쓰고있고, 잘 모르니 일단 둘 다 했다. 내가 이해하는 선에선, 위에가 기본 터미널이고 아래가 iTerm 설정이라고 알고있다.
2. 코드 따라하기
(1) 라이브러리 설치
일단 블로그에 나온 라이브러리를 다 설치했다.
$ pip install bs4
$ pip install selenium
$ pip install requests
$ pip install pandas
라이브러리가 모두 설치됐으니 news_scraper.py 파일을 만들어서 라이브러리를 import 해준다.
# news_scraper.py
# library import
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pandas as pd
import requests
(2) 검색어 설정
처음 의도한대로 input() 함수를 사용해서 검색어를 입력해서 저장할 수 있게 다음과 같이 코드를 넣었다.
keywords = input('Search keyword: ')
이제 검색하려는 단어들, 검색식은 keywords 변수에 저장될 것이다.
(3) chromedriver 호출 및 Google News 주소 입력
다른 사람들의 예제를 참고해서 다음 내용을 추가해줬다.
driver = webdriver.Chrome('chromedriver')
driver.get('https://news.google.com/?hl=ko&gl=KR&ceid=KR%3Ako')
driver.implicitly_wait(3)
일단 Google News의 주소를 https://news.google.com/?hl=ko&gl=KR&ceid=KR:ko로 추가해준다. 그냥 https://news.google.com로 해주니깐 한글 키워드 입력시 문제가 발생했다.
(3)-1 time.sleep vs driver.implicitly_wait()
driver.implicitly_wait(3) 대신에 time.sleep(3)을 해도 같은 효과라고 하던데 검색을 해보니까5 두 개의 차이가 있었다.
timm.sleep()은 무조건 정해진 시간만큼 대기하고, driver.implicitly_wait()은 “브라우저에서 사용되는 엔진 자체에서 파싱되는 시간을 기다려 주는 메소드” 라고 한다. 정해진 시간만큼 대기하다가 그 사이에 파싱이 되면 다음 단계로 넘어간다고 한다.
(4) 검색창의 xpath 확인과 검색어 입력 및 실행
검색창의 xpath는 다음 그림과 같이 확인을 해준다. 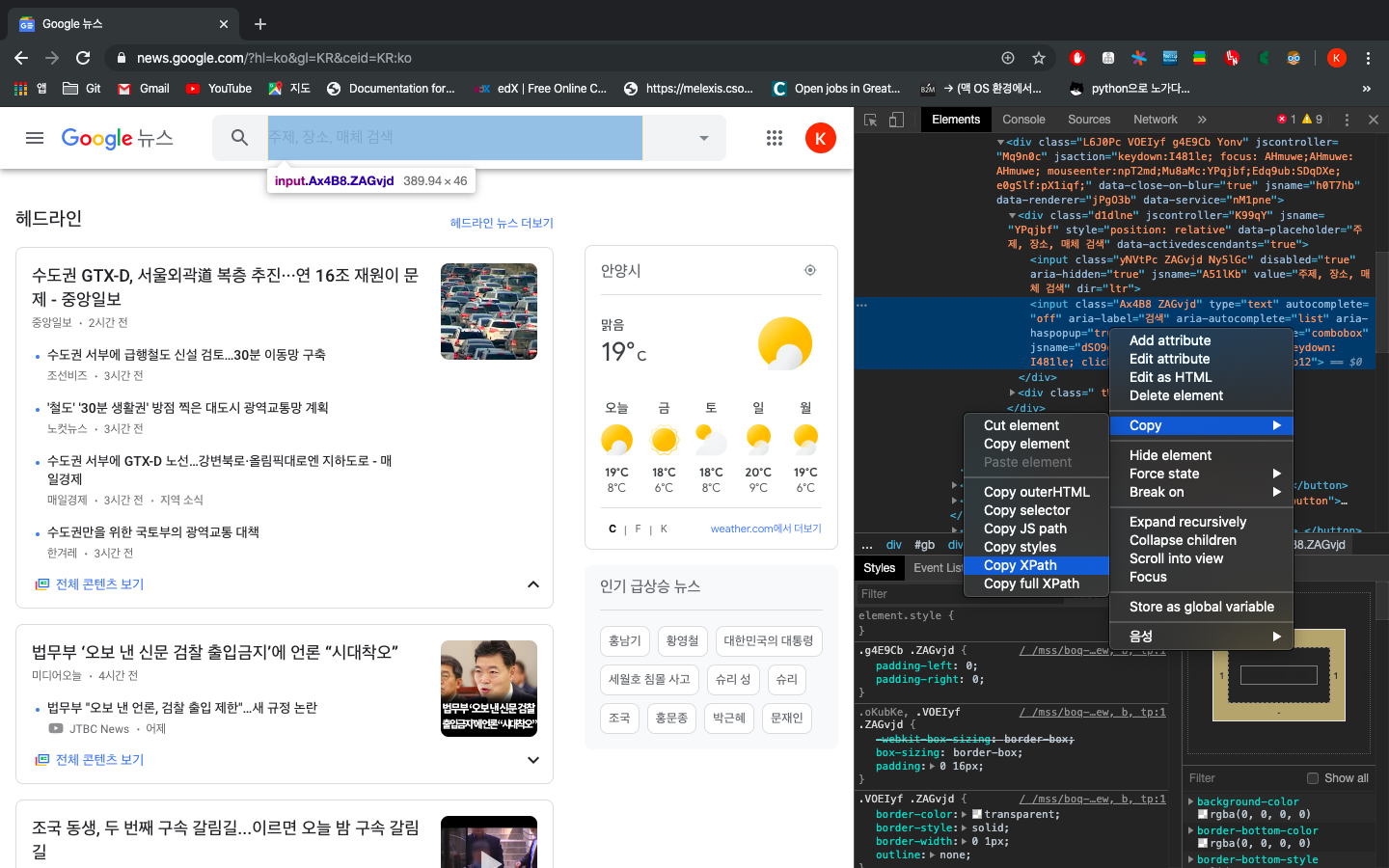
그렇게 확인한 xpath를 driver.find_element_by_xpath()로 받아서 search 변수에 저장한다. 그리고 실행할 동작들을 지정하여 코드를 작성했다.
search = driver.find_element_by_xpath(
'//*[@id="gb"]/div[2]/div[2]/div/form/div[1]/div/div/div/div/div[1]/input[2]')
search.send_keys(keywords)
search.send_keys(Keys.ENTER)
driver.implicitly_wait(30)
키워드를 받아서 입력하고 실행한 후 결과물을 파싱하기도 전에 코드가 진행되지 않을까 하는 노파심에 넉넉히 30초 시간을 줬다.
(5) 검색 결과 페이지 파싱하기
검색 결과에서 타이틀과 링크를 저장하는 것이 목표이므로 검색 결과 페이지의 주소를 확인하고 requests를 이용해서 페이지의 내용을 가져온다. 그 다음 BeautifulSoup를 이용해서 페이지 내용을 lxml로 파싱해준다.
url = driver.current_url
resp = requests.get(url)
soup = bs(resp.text, 'lxml')
(6) 제목과 링크 구분하기
제목, 주소의 빈 리스트 자료형을 만들어준 후 for문을 이용해서 제목과 링크 만 추출하여 리스트 자료형에 append한다.
titles = []
links = []
for link in soup.select('h3 >a'):
href = 'https://news.google.com' + link.get('href')[1:]
title = link.string
titles.append(title)
links.append(href)
Chrome의 개발자 도구로 열어주면 기사의 제목과 링크가 있는 부분을 확인할 수 있는데, h2 태그에 있는 내용을 select로 가져온다. 정확한 사용법이나 내용을 이해하진 못했는데 여기 나와있는 설명6을 읽어보고 ‘아.. 그렇구나….’ 하고 넘어갔다.
링크를 가져올 때 [1:]로 설정한 이유는, 개발자 도구에 보면 링크 주소 맨 앞에 시작이 ./로 되어있어서 href 내용을 전부 가져오면 링크가 오류나서 저렇게 설정해줬다.
(7) 파일로 저장하기
이 부분은 블로그에서 사용한 방법 그대로 응용했다. pandas를 써본적이 없는데, 찾아보니 데이터 분석할 때 쓰는 라이브러리라고 한다. 내가 코드를 이해하기론, 제목과 링크를 딕셔너리 자료형으로 만들어서 data 변수에 저장한 후 입력한 검색어를 파일명으로 해서 *.csv와 *.xlsx로 저장하게끔 만들어주는 기능인 것 같다. 나중에 언젠간 더 써먹을 일이 있을것 같다.
저장하고 모든 동작이 완료됐으면 "Complete!"을 출력하도록 간단한 print문 추가해주고 마무리했다.
data = {'title': titles, 'link': links}
data_frame = pd.DataFrame(data, columns=['title', 'link'])
data_frame.to_csv('./' + keywords + '.csv')
data_frame.to_excel('./' + keywords + '.xlsx')
print("Complete!")
3. 최종 결과물
최종 결과물을 확인하기 위해서 터미널에서 news_scraper.py를 실행해서 내 전공 분야인 Atomic Layer Deposition을 검색해보기로 한다.
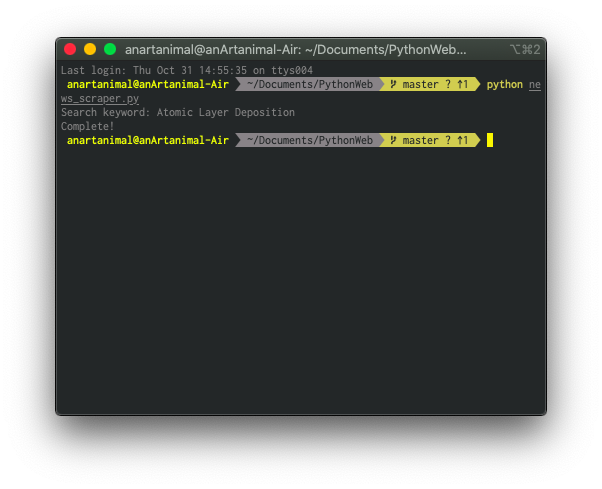
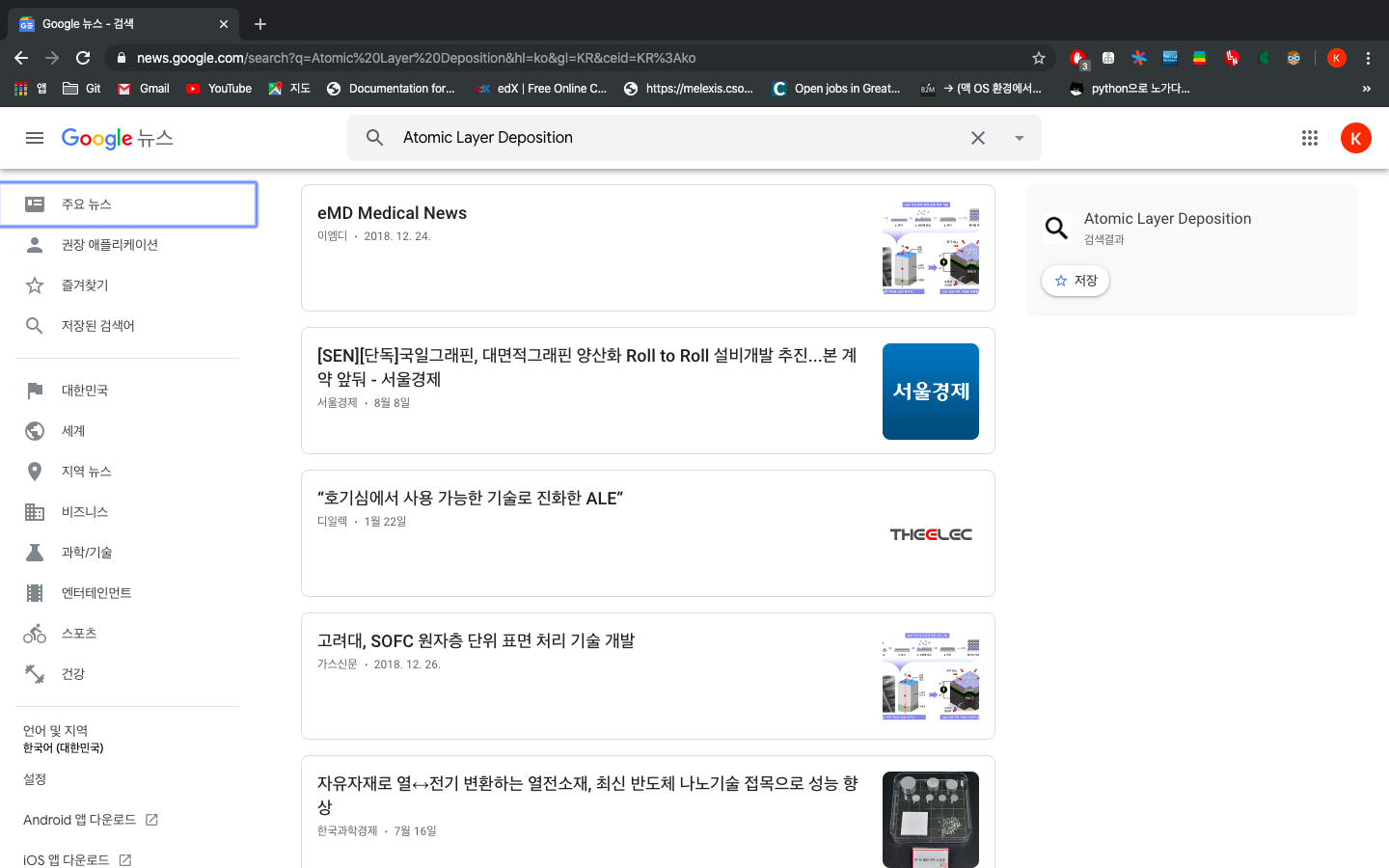
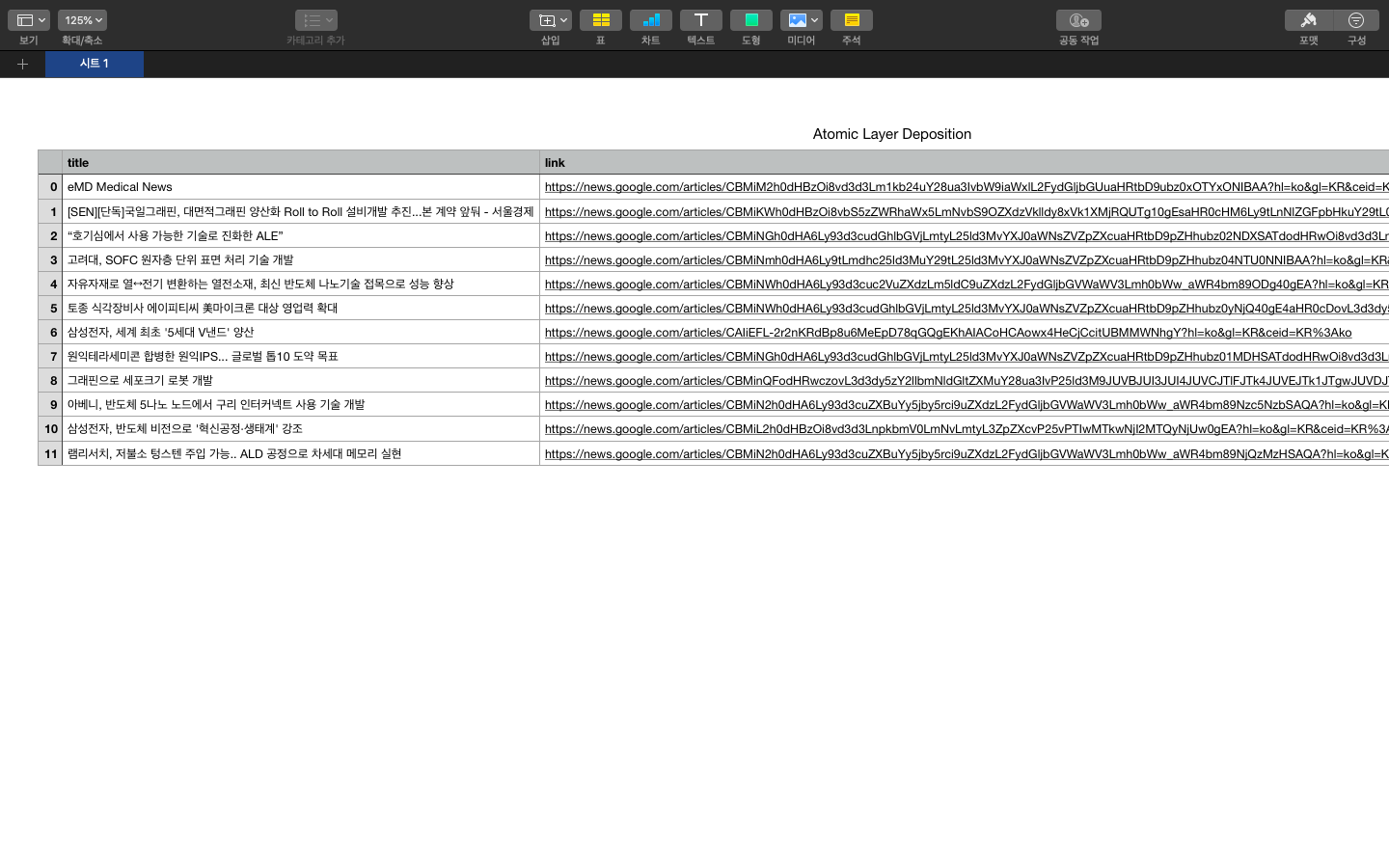
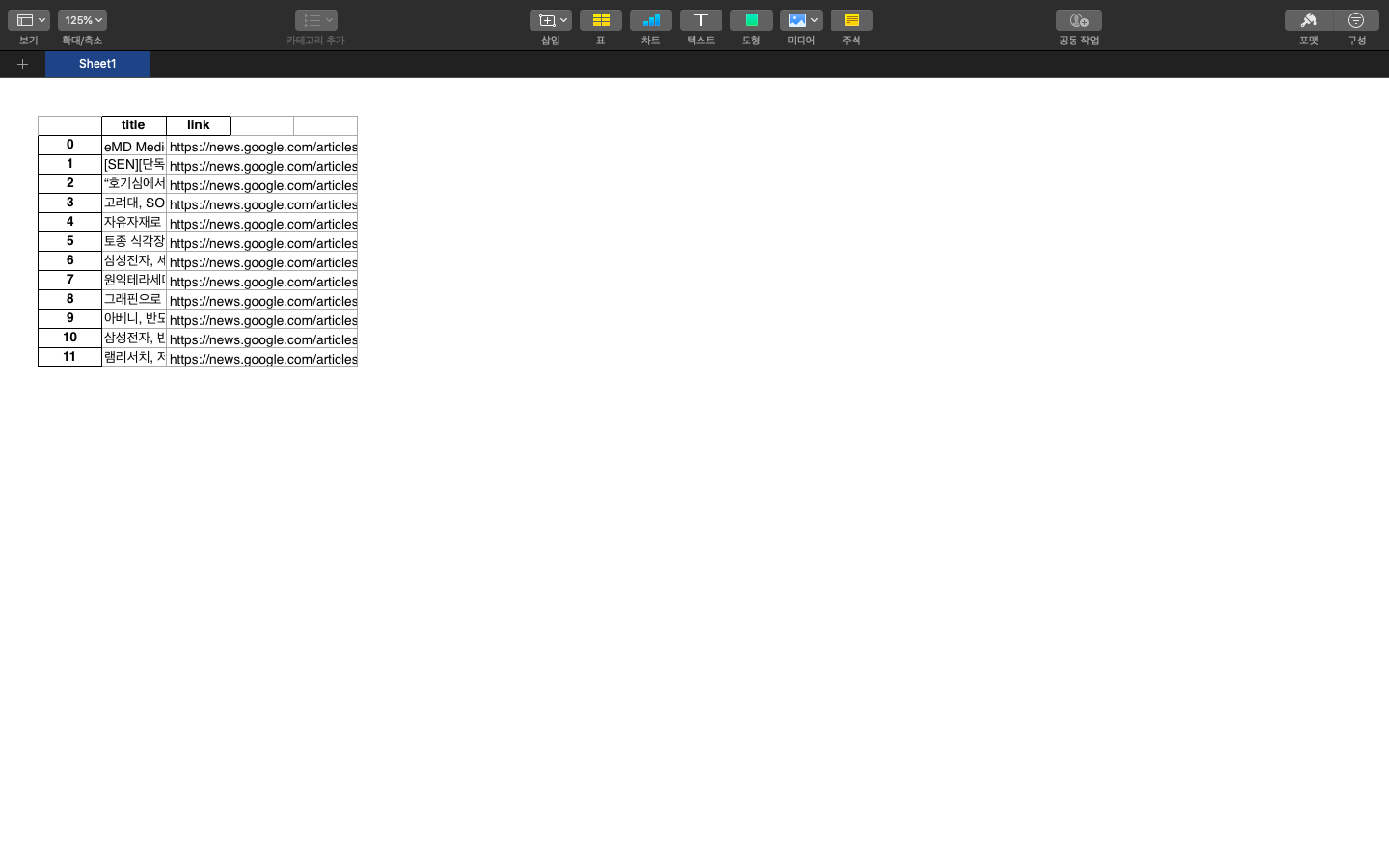
PROFIT!!
제대로 돌아가는 것을 확인할 수 있다. 다음에는 파일명에 공백이나 특수문자가 들어갈 경우 정규식을 이용해서 바꿔서 저장하는 기능까지 도전해봐야겠다.
csv 파일과 xlsx 파일, py 파일은 여 기 서확인할 수 있다.
최종 코드는 다음과 같다 (클릭)
# https://hsj00.github.io
# news_scraper.py
# library import
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pandas as pd
import requests
# 검색어 입력
keywords = input('Search keyword: ')
# 웹드라이버 옵션
options = webdriver.ChromeOptions()
options.headless = True
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36")
# 웹드라이버 호출
driver = webdriver.Chrome('chromedriver', options=options)
driver.get('https://news.google.com/?hl=ko&gl=KR&ceid=KR%3Ako')
driver.implicitly_wait(3)
# Google News 검색창 Xpath
search = driver.find_element_by_xpath(
'//*[@id="gb"]/div[2]/div[2]/div/form/div[1]/div/div/div/div/div[1]/input[2]')
# 검색어 입력 및 실행
search.send_keys(keywords)
search.send_keys(Keys.ENTER)
driver.implicitly_wait(30)
# 현재 주소 가져오기
url = driver.current_url
# 현재 주소로부터 'lxml' 파싱
resp = requests.get(url)
soup = bs(resp.text, 'lxml')
# 제목, 주소의 빈 리스트 자료형 만들기
titles = []
links = []
# `lxml` 파싱한 결과물에서 제목과 링크 추출 후 데이터로 저장
for link in soup.select('h3 > a'):
href = 'https://news.google.com' + link.get('href')[1:]
title = link.string
titles.append(title)
links.append(href)
data = {'title': titles, 'link': links}
data_frame = pd.DataFrame(data, columns=['title', 'link'])
data_frame.to_csv('./' + keywords + '.csv')
data_frame.to_excel('./' + keywords + '.xlsx')
print("Complete!")
번외편. Headless 설정 추가하기
실행할 때마다 창을 띄우는게 싫어서 여길7 참고해서 코드를 추가했다. 여기 나와있는 코드대로 하면 에러가 나서 구글링해준 다음에 살짝 수정했다.
options = webdriver.ChromeOptions()
options.headless = True
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36")
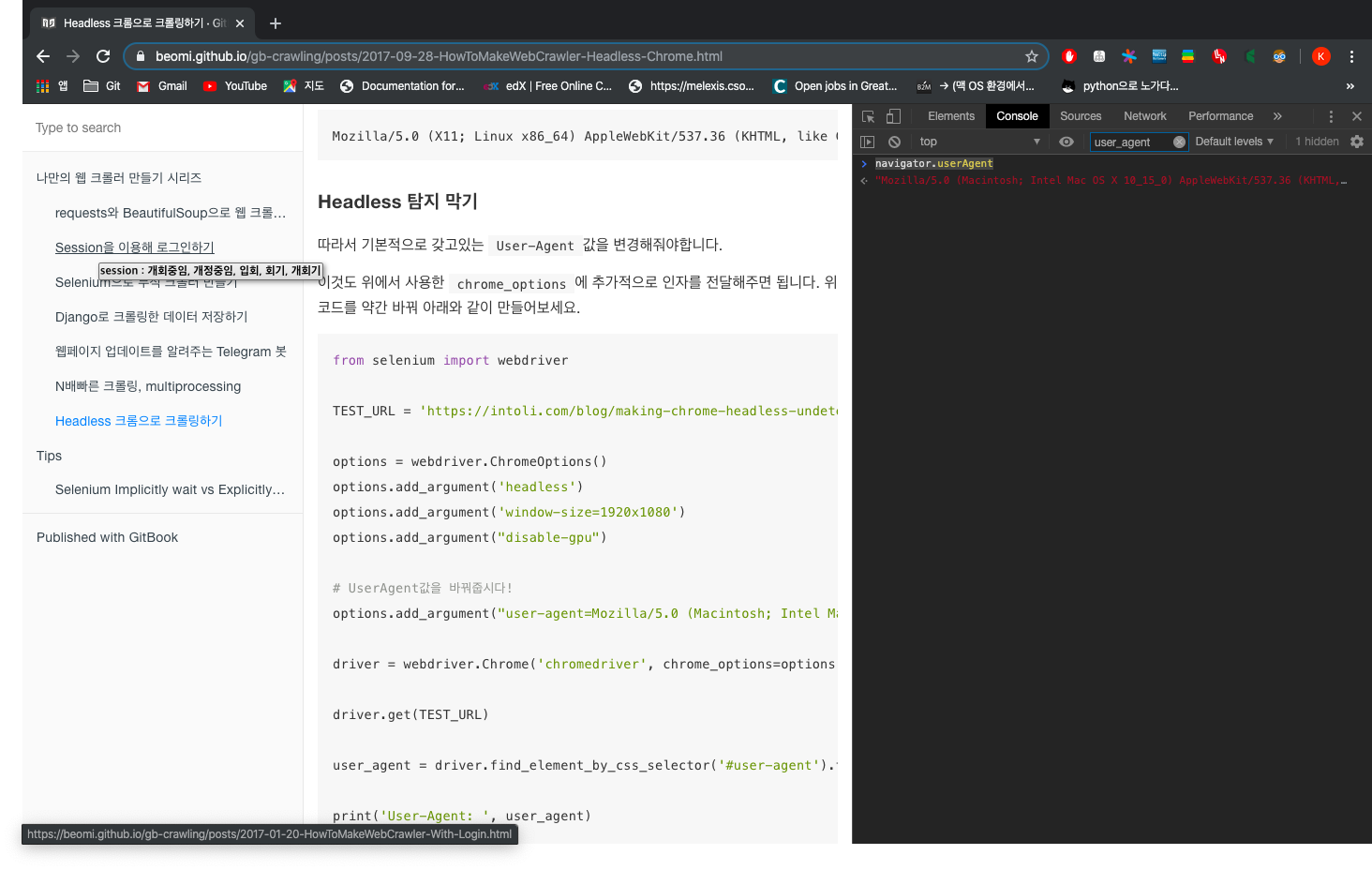
블로그와 다른 부분은 options.headless = True로 바꿔준 것과, user-agent 부분을 변경해준 것이다. 개발자 도구를 열어 Console에서 navigator.userAgent라고 치면 값이 나온다. 그 값으로 바꿔서 입력했다. 이렇게 해주면 스크랩할 때 headless인걸 인식하지 못한다나….
그리고 chrome_options=가 아니라 options=로 바꿔줘야 한다. 왜냐하면…!!
DeprecationWarning: use options instead of chrome_options
driver = webdriver.Chrome('chromedriver', chrome_options=options)
이런 메시지가 나오기 때문이다.
-
https://blog.naver.com/PostView.nhn?blogId=okkam76&logNo=221300244255&parentCategoryNo=&categoryNo=21&viewDate=&isShowPopularPosts=false&from=postView ↩
-
https://horae.tistory.com/entry/PYTHON-3-Tutorials-24-%EC%9B%B9-%ED%81%AC%EB%A1%A4%EB%9F%AClike-Google-%EB%A7%8C%EB%93%A4%EA%B8%B0-1-How-to-build-a-web-crawler ↩
-
https://wikidocs.net/book/2965 ↩
-
https://beomi.github.io/2016/12/27/Django-TDD-Study-01-Setting-DevEnviron/ ↩
-
https://www.a-ha.io/questions/4d1c8589dcb22246af4a4d4960834bcf ↩
-
https://m.blog.naver.com/PostView.nhn?blogId=kiddwannabe&logNo=221177292446&proxyReferer=https%3A%2F%2Fwww.google.com%2F ↩
-
https://beomi.github.io/gb-crawling/posts/2017-09-28-HowToMakeWebCrawler-Headless-Chrome.html ↩
Enjoy Reading This Article?
Here are some more articles you might like to read next: